Wie können Unternehmen KI-gestützte Anwendungen zuverlässig schützen? In unserem Folgeartikel in „JavaSPEKTRUM“ setzen wir die Betrachtung zur sicheren Integration von Large Language Models (LLMs) fort – diesmal mit Fokus auf die konkreten Gegenmaßnahmen. Mit dem OWASP-Katalog für LLMs und dem bewährten Threat Modelling Prozess liefern wir praxisnahe Antworten auf die neuen technologischen Herausforderungen. Der interne Chatbot, das zentrale Szenario der Artikelreihe (im vorherigen Artikel eingeführt), bleibt unser roter Faden: Ein LLM-Agent kommuniziert mit einem externen Modell und greift mithilfe eines RAG-Systems auf Firmenwissen zu.
(Weitere) Risiken im Unternehmensalltag
Betrachten wir zunächst weitere Risiken bei der Integration von LLMs in Anwendungen: Erstens führt die Gefahr von Fehlinformationen dazu, dass LLMs mitunter plausibel klingende, aber falsche Ausgaben liefern. Ursache sind meist lückenhafte oder veraltete Trainingsdaten; verlässt sich ein Nutzer darauf, entstehen potenziell rechtliche oder sicherheitsrelevante Folgen. Zweitens birgt das „Poisoning“ von Trainingsdaten Risiken für die Integrität des Modells. Werden öffentliche Datenquellen manipuliert, gelangen versteckte Backdoors ins Modell – Angreifer könnten auf diesem Weg gezielt falsche Antworten provozieren. Drittens schafft die hohe Komplexität der Supply Chain neue Schwachstellen. Externe Komponenten wie Cloud-Infrastruktur oder Open-Source-Modelle sind schwer durchgängig zu prüfen; intransparente Herkunft und nachträgliche Modifikationen der Modelle machen eine umfassende Bewertung problematisch.
Schutzmaßnahmen in der Praxis
Die Strategie zur Absicherung von LLM-Anwendungen basiert auf konkreten Maßnahmen, die anhand von Beispielen vorgestellt werden. Zunächst verstärken Guardrails die Sicherheit gegen Prompt Injection. Sie filtern Anfragen nach problematischen Mustern und ermöglichen so das frühzeitige Blockieren manipulativer Eingaben – zusätzliche maschinelle Lernverfahren erhöhen die Flexibilität dieser Filter. Man muss jedoch dazu sagen, dass Guardrails alleine keinen absoluten Schutz gegen Prompt Injection bieten, sondern nur unterstützend wirken können. Laut aktuellem Stand der Forschung wird teilweise sogar vermutet, dass Guardrails konzeptuell keinen 100%igen Schutz liefern können.
Daher müssen zusätzlich explizite Schutzmaßnahmen getroffen werden: Feingranulare Zugriffskontrollen sorgen für die sichere Speicherung und Verwendung von Unternehmenswissen. Hinterlegte Rechte in der RAG-Datenbank und konsequente Überprüfung der Nutzeranfragen verhindern, dass sensible Informationen versehentlich freigegeben werden. Zusätzlich steigt die Effizienz der Erkennung und Reaktion auf Angriffe durch gezieltes Monitoring und Logging. Verdächtige Nutzeraktivität oder auffälliges Verhalten des LLMs lässt sich durch Protokollierung aufdecken, sodass Gegenmaßnahmen rechtzeitig greifen.
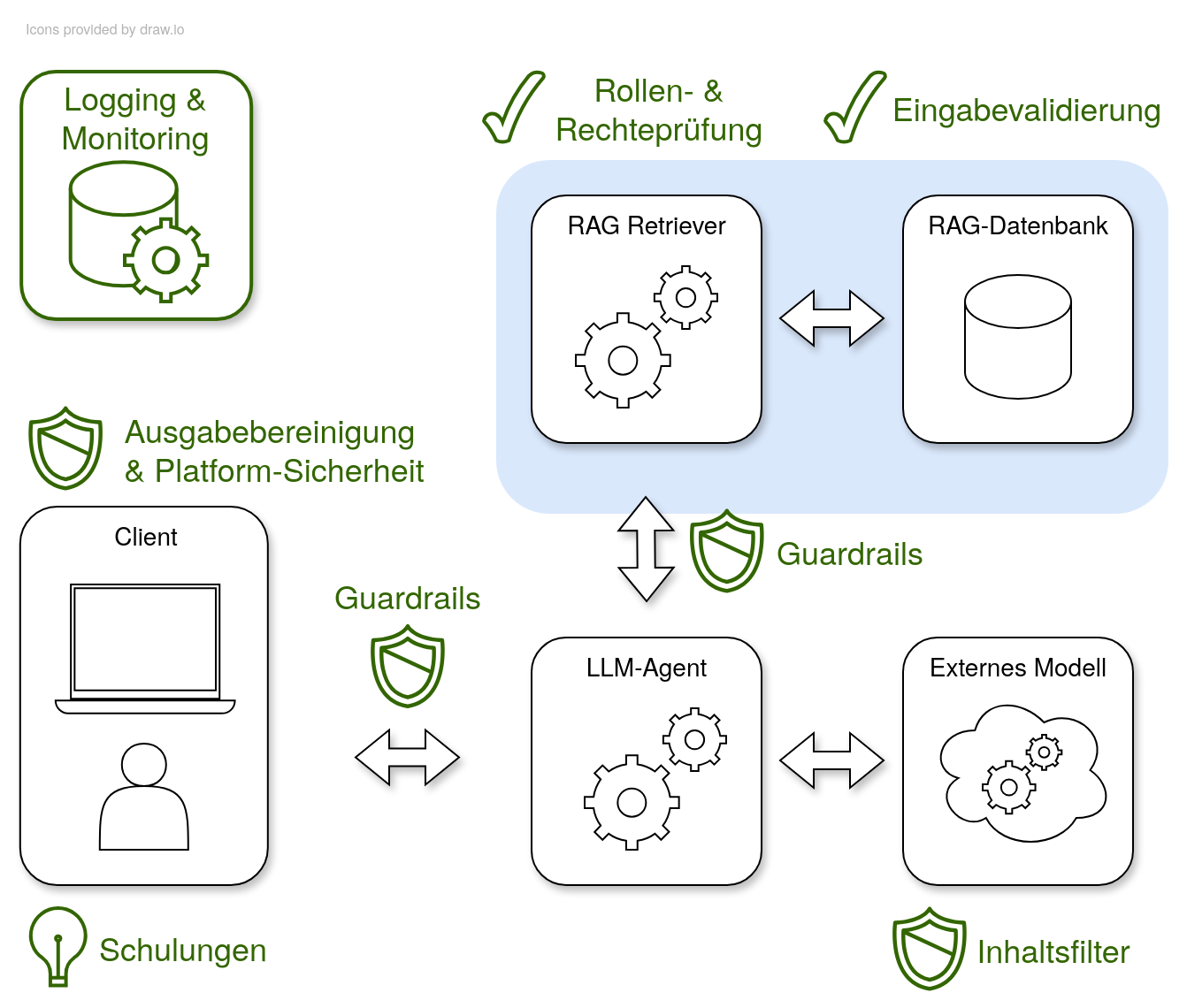
Möchte ein Mitarbeiter nun Informationen aus dem Chatbot abfragen, wird die Anfrage zunächst durch den LLM-Agenten entgegengenommen. Danach wird der RAG-Retriever verwendet, welcher die für die Anfrage relevantesten Dokumente aus der RAG-Datenbank heraussucht. Dies wird semantische Suche genannt. Diese werden als Kontext zur Anfrage des Mitarbeiters hinzugefügt und an das LLM gegeben. Dieses kann dann durch den Kontext eine relevante Antwort generieren.
Auch im Umgang mit Nutzereingaben und generierten Ausgaben helfen erprobte Prinzipien, das Sicherheitsniveau zu steigern. Eine strenge Eingabevalidierung minimiert Injection-Risiken in das System. Klare Datenflüsse und sichere Ausgabefunktionen verhindert die Einbettung schädlicher Inhalte. Beispiel: Nur erlaubte Dateiformate und Zeichensätze gelangen ins System, unerwartete oder schädliche Inhalte werden zuverlässig abgelehnt. Zweitens reduziert eine kontextbasierte Ausgabebereinigung die Gefahr von Angriffen im Zielsystem. Das Entfernen oder Entschärfen gefährlicher Bestandteile – etwa von Script-Tags – schützt vor Ausnutzung durch Cross-Site-Scripting. Drittens schafft kontinuierliche Protokollierung und Überwachung Transparenz. Durch konsequentes Logging werden Anomalien sichtbar; – Beispiele aus der Praxis zeigen, wie Unternehmen dadurch frühzeitig auf verdächtige Aktivitäten reagieren können.
Fazit: Mit Prinzip und Methode zum sicheren LLM-Betrieb
Abschließend lässt sich festhalten: Wer den Einsatz von LLMs konsequent begleitet und die Schutzmechanismen regelmäßig überprüft, mindert Risiken effektiver. Eine dreistufige Herangehensweise aus Filterung, Zugriffskontrolle und Monitoring entscheidet über die Sicherheit in Business-Prozessen. Beispiele aus der Unternehmenspraxis belegen, wie Sicherheitsteams durch klare Zuständigkeiten kombiniert mit Schulungen eine nachhaltige Sicherheitskultur schaffen. KI-gestützte Anwendungen können so risikobewusst und vertrauenswürdig betrieben werden – das ist die zentrale Basis für den Schritt in die Zukunft.
Der Artikel erschien in der September Ausgabe von Java Spektrum
